Jubaclassifier Hands-on¶

Agenda¶
- 分類とは
- 実際に動かしてみる
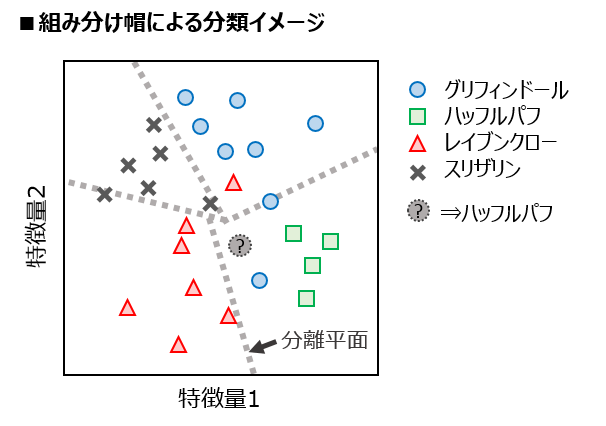
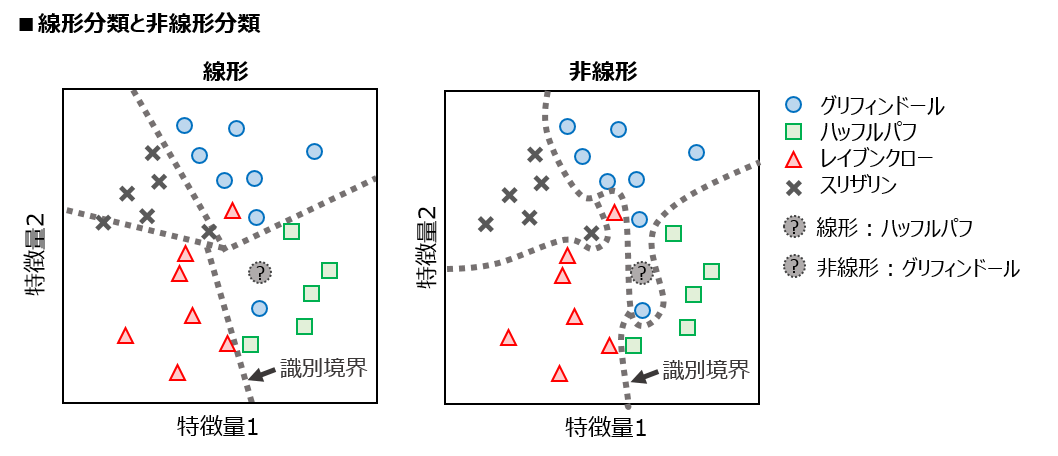
線形分類器 VS 非線形分類器¶
- 線形分類器 : 空間を直線/平面で区切っていく
- シンプルで早いが、どうしても分けられない場合も出てくる
- 非線形分類器 : 空間を曲線/曲面で区切っていく
- 精度はいいが、過学習の恐れあり
実際に動かしてみる¶
実際にjubaclassifierを動かすことで、 Jubatusについて、分類について学んでいきましょう。
立ち上げ¶
用意したdockerの人¶
下記コマンドを実施
$ docker run -p 8888:8888 -it jubatus/hands-on-5th /bin/bash $ jupyter notebook &http://127.0.0.1:8888 にアクセス
VM、すでに環境がある人¶
- hands-on-5thフォルダまで行き、jupyter notebookを立ち上げる
手順¶
- Step0. 環境の確認
- Step1. Jubatusの起動
- Step2. データの読み込み、Datumに変換
- Step3. 作成したDatumをJubatus
- Step4. 学習モデルを用いて分類を行う
- Step5. 結果の分析をしてみる
- Step6. 前処理をしてみる
- Step7. 指標のトレードオフ
Step0. 環境の確認¶
環境に、以下のものが入っているか確認してください。
- Jubatus
- Pythonライブラリ(jubaclassifierハンズオン用)
jupyter,jubatus,scikit-learnnumpy,pandas,matplotlib
- Pythonライブラリ(Jubakit, Python pluginハンズオン用)
jubakit,Cython,embedded_jubatus,statsmodels
配布物¶
下記のものがフォルダhands-on-5th/classifier内にあるか確認してください。
- スクリプト(Python Notebookで配布します)
hands_on.ipynb
- データ(data/配下)
default_train.csvdefault_test.csv
- コンフィグファイル(config/配下)
linear.json(AROW)nonlinear.json(NN/Euclid LSH)
Step1. Jubatusを起動¶
- ターミナルに戻り、下記コマンドを入力します
- 線形分類器(AROW)を使ってみます

Step2. データを読み込み、Datumに変換¶
- 今回扱うデータ : default of credit card clients Data Set
- 台湾の顧客に対し、支払いの不払い(デフォルト)があったかどうかを集めたデータ
- 年齢や性別など、23個の特徴量で構成されている
※本とは違うデータを用いています。
前処理等で、コードが少し異なる箇所もありますが、流れは本のままです。
DEFAULTに支払いが履行されたかどうかの情報が含まれているDEFAULTを分類器の答え合わせ(正解ラベル)に用いる
| 列番 | 特徴量 | 概要 | 特徴量の型 |
|---|---|---|---|
| X1 | Amount of the given credit | 信用貸付額 | 整数 |
| X2 | Gender | 性別 | カテゴリ変数 |
| X3 | Education | 学歴 | カテゴリ変数 |
| X4 | Martial status | 結婚歴 | カテゴリ変数 |
| X5 | Age | 年齢 | 整数 |
| X6-X11 | History of past payment | 過去の支払い。きちんと支払ったかどうか(※1) | 整数 |
| X12-X17 | Amount of bill statememt | 過去の請求額(※1) | 整数 |
| X18-X23 | Amount of previous payment | 過去の支払額(※1) | 整数 |
| Y | DEFAULT | デフォルトしたかどうか | カテゴリ変数(正解ラベル) |
※1 2005年4月から2005年9月までの6ヶ月分のデータ
Pandasを使ってデータを読み込んでみる¶
In [2]:
import pandas as pd
df = pd.read_csv("data/default_train.csv") #データの読み込み
df.head()
Out[2]:
データの読み込み¶
- pandasを用いてデータを読み込む
- 特徴量ベクトル, ラベル, 特徴量の名前をcsvから出力
In [3]:
def read_dataset(path):
df = pd.read_csv(path)
labels = df['Y'].tolist()
df = df.drop('Y', axis=1)
features = df.as_matrix().astype(float)
columns = df.columns.tolist()
return features, labels, columns
features_train, labels_train, columns = read_dataset("data/default_train.csv")
In [4]:
print("columns : \n{}\n".format(columns))
print("features : \n{}".format(features_train))
学習用データをDatum形式に変換¶
- Jubatusにデータを投げるために、pandasで読み込んだデータをDatum形式にする必要がある
- データと正解ラベルを1セットにしてデータを保持
In [5]:
from jubatus.common import Datum
features_train, labels_train, columns = read_dataset('data/default_train.csv')
train_data = []
for x, y in zip(features_train, labels_train):
d = Datum({key: float(value) for key, value in zip(columns, x)})
train_data.append([str(y), d])
Step3. 作成したDatumをJubatusサーバに投入¶
In [6]:
from jubatus.classifier.client import Classifier
# Jubatusサーバのホストとポートを指定する
client = Classifier('127.0.0.1', 9199, '')
#過去の学習結果を一度初期化する(任意)
client.clear()
# 学習を実行
client.train(train_data)
Out[6]:
Step4. 学習モデルを用いて分類を行う¶
- 作った学習モデルを使って、実際に分類をしてみる
data/default_test.csvを用いる
※実際の評価の際は、Cross Validationなどがよく使われます。
In [7]:
# テスト用Datumリストを作る
features_test, labels_test, columns = read_dataset('data/default_test.csv')
test_data = []
for x, y in zip(features_test, labels_test):
d = Datum({key: float(value) for key, value in zip(columns, x)})
test_data.append(d)
テストをする¶
実際にJubaclassifierにデータを投入し、返ってくるラベルを見る
In [8]:
# テストをする
results = client.classify(test_data)
Jubatusがdefaultに対して、
yes/noどちらが可能性が高いかをスコアリングしてくれている
In [9]:
results[0]
Out[9]:
Step5. 結果の分析を行う¶
- 先ほどのスコアの大きい方を分類結果として返す
get_most_likely関数を作る - 結果の混合行列, accuracy, precision, recall, F-valueを算出する
In [10]:
# 結果を分析する(スコアの大きい方のラベルを選ぶだけ)
def get_most_likely(result):
return max(result, key = lambda x: x.score).label
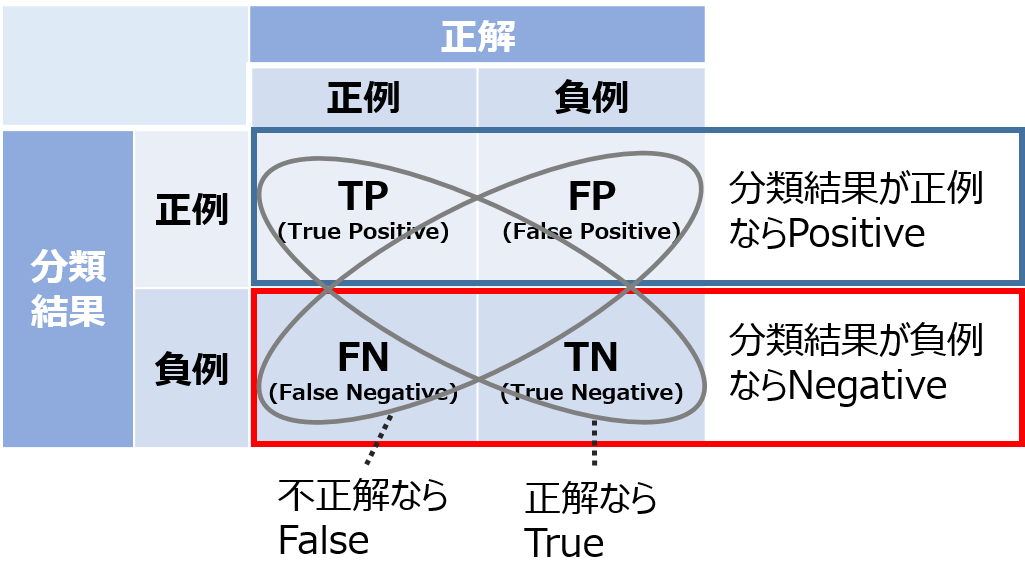
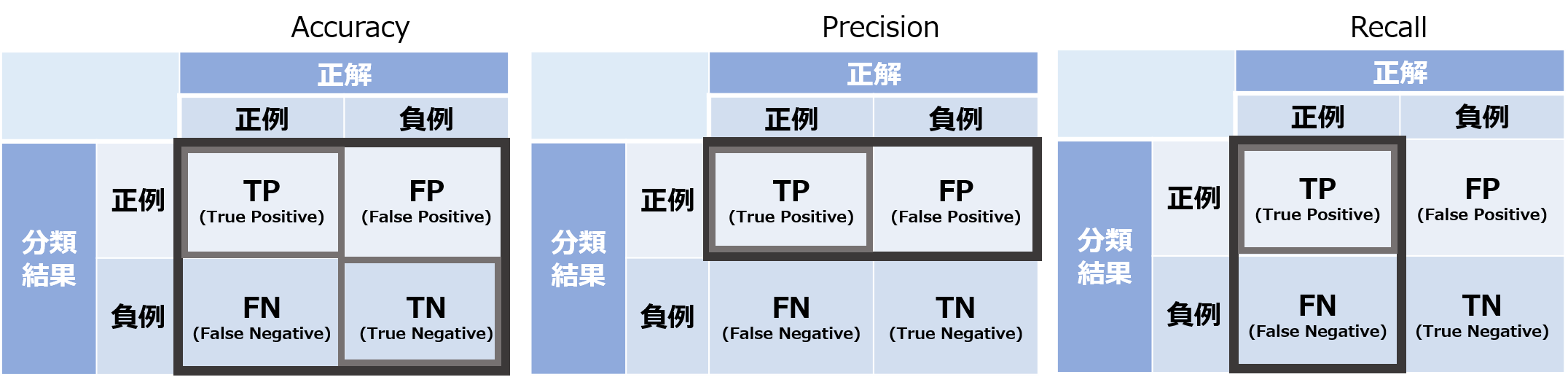
分類結果の評価指標¶
- 分類結果は、
正例か負例かという観点と、
答えが合ってたかどうかという観点で4種類に分けられる - 分類した結果が...
- Default 有 : 正例(Positive)
- Default 無 : 負例(Negative)
- 推定結果が...
- 正しい : True
- 間違ってる : False
In [11]:
def analyze_results(labels, results, pos_label="1", neg_label="0"):
tp, fp, tn, fn = 0, 0, 0, 0
for label, result in zip(labels, results):
estimated = get_most_likely(result)
label = str(label)
estimated = str(estimated)
if label == pos_label and label == estimated:
tp += 1
elif label == pos_label and label != estimated:
fn += 1
elif labels != pos_label and label == estimated:
tn += 1
else:
fp += 1
accuracy = float(tp + tn) / float(tp + tn + fp + fn)
precision = float(tp) / float(tp + fp)
recall = float(tp) / float(tp + fn)
f_value = 2.0 * recall * precision / (recall + precision)
# confusion matrix
confusion = pd.DataFrame([[tp, fp], [fn, tn]], index=[pos_label, neg_label], columns=[pos_label, neg_label])
return confusion, accuracy, precision, recall, f_value
In [12]:
confusion, accuracy, precision, recall, f_value = analyze_results(labels_test, results)
print('confusion matrix\n{0}\n'.format(confusion))
print('metric : score')
print('Accuracy : {0:.3f}'.format(accuracy))
print('Precision : {0:.3f}'.format(precision))
print('Recall : {0:.3f}'.format(recall))
print('F_value : {0:.3f}'.format(f_value))
Step6. 前処理をしてみる¶
- Accuracyが高いにも関わらず、Recallが低い
- Recall : Defaultする人に対し、Defaultしたと予測できているか
- Recallが低い
=> Defaultするはずの人を捉えられていない
=> リスク管理できない!
- Recallが低い
Recallを上げるために => アンダーサンプリング¶
In [13]:
print(df[df["Y"]==0].shape)
print(df[df["Y"]==1].shape)
- 現状
- 正例(defaultした) : 5577件
- 負例(defaultしていない) : 19421件
- 負例に引きずられて、分類がうまくいっていない可能性あり
In [14]:
import random
random.seed(42) # シードで乱数を固定(再現性を得たい場合に実行)
def under_sampling(features, labels, reduce_label, reduce_rate=0.2):
sampled_features, sampled_labels = [], []
for feature, label in zip(features, labels):
label = str(label)
if label != reduce_label or random.random() < reduce_rate:
sampled_features.append(feature)
sampled_labels.append(label)
return sampled_features, sampled_labels
In [15]:
# アンダーサンプリング
reduce_rate = 0.2
sampled_features_train, sampled_labels_train = under_sampling(features_train, labels_train,
reduce_label="0",reduce_rate=reduce_rate)
# 学習用Datumリストを作る
sampled_train_data = []
for x, y in zip(sampled_features_train, sampled_labels_train):
d = Datum({key: float(value) for key, value in zip(columns, x)})
sampled_train_data.append([str(y), d])
# 学習をする
client = Classifier('127.0.0.1', 9199, '')
client.clear()
client.train(sampled_train_data)
# テストをする
results = client.classify(test_data)
In [16]:
# 結果を分析する
confusion, accuracy, precision, recall, f_value = analyze_results(labels_test, results)
print('confusion matrix\n{0}\n'.format(confusion))
print('metric : score')
print('accuracy : {0:.3f}'.format(accuracy))
print('precision : {0:.3f}'.format(precision))
print('recall : {0:.3f}'.format(recall))
print('f_value : {0:.3f}'.format(f_value))
Step7. 指標のトレードオフ¶
- PrecisionとRecallはトレードオフの関係にある
| metric | score normal |
score under sampling |
|---|---|---|
| Accuracy | 0.803 | 0.542 |
| Precision | 0.568 | 0.276 |
| Recall | 0.291 | 0.716 |
| f_value | 0.385 | 0.398 |
In [17]:
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
rs = np.linspace(0,1.0,11)
precisions = []
recalls = []
In [18]:
for r in rs:
sampled_features_train, sampled_labels_train = under_sampling(features_train, labels_train, reduce_label="0",reduce_rate=r)
# 学習用Datumリストを作る
sampled_train_data = []
for x, y in zip(sampled_features_train, sampled_labels_train):
d = Datum({key: float(value) for key, value in zip(columns, x)})
sampled_train_data.append([str(y), d])
# 学習をする
client = Classifier('127.0.0.1', 9199, '')
client.clear()
client.train(sampled_train_data)
# テストをする
results = client.classify(test_data)
confusion, accuracy, precision, recall, f_value = analyze_results(labels_test, results)
precisions.append(precision)
recalls.append(recall)
# print(confusion)
print("rate:{:.1f} precision:{:.2f} recall:{:.2f} accuracy:{:.2f} f-value:{:.2f}".format(r, precision, recall, accuracy, f_value))
In [19]:
plt.figure(figsize=(8,8))
plt.plot(rs, precisions,"o-",alpha=0.5,label="precision")
plt.plot(rs,recalls,"o-",alpha=0.5,label="recall")
plt.xlim(0,1)
plt.ylim(0,1)
plt.legend()
plt.show()

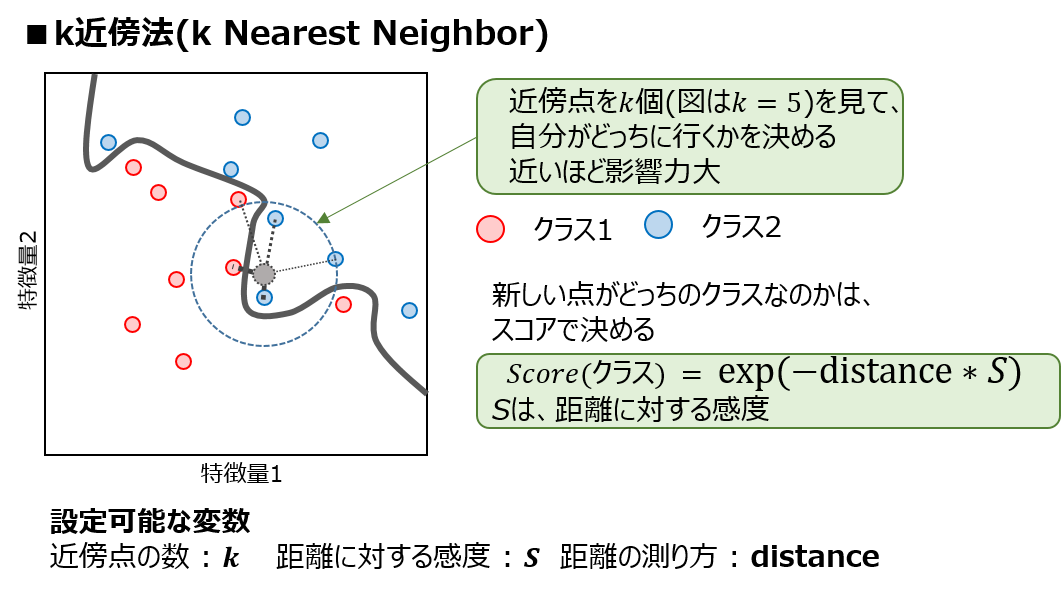
非線形分類器のパラメータ¶
まとめ¶
- Jubatusを使って分類をやってみた
- 分類の評価指標はたくさんあるので、目的に合わせて選ぶ
- データをうまく処理することで、線形分類器でも精度を上げることが可能